Finite Difference Flow Optimization
RL Post-Training for Flow-Based Image Generators
 Epoch 0
Epoch 0  Epoch 50
Epoch 50 In this project, we set out to find a simple, grounded RL post-training method for diffusion image generators. We made a few observations about the structure of diffusion flows that lead to Finite Difference Flow Optimization (FDFO), a new online RL algorithm that reduces variance in the model updates by sampling paired trajectories and pulling the flow velocity in the direction of the more favorable image. In our experiments, FDFO converges faster, reaches higher rewards, and produces fewer artifacts than current solutions.
Diffusion models fit the distribution of their training data conservatively. This means they assign non-zero likelihood to images that are near the data manifold but not on it, resulting in a distribution that envelops the natural image manifold but produces many low-quality samples




This motivates the use of methods to sharpen the distribution. The dominant approach is classifier-free guidance (CFG)
Why Apply RL to Image Generation?
In LLMs, RL post-training is a standard tool today. Pretraining produces a model with broad coverage but a loose, unfocused output distribution. Post-training techniques like RLHF
It isn’t obvious how to apply RL to diffusion and flow models. Standard RL machinery was built for domains where model likelihoods are easily accessible, but these are notoriously difficult to estimate in continuous flows. Most existing approaches work around this by forcing the flow into a Markov decision process (MDP) framework with ungrounded proxy likelihoods. A natural question is whether we can ascend the reward gradient, the stated goal of policy gradient methods, in a more flow-native way.
Previously, I (David) worked on applying policy gradients to flow matching for continuous control with FPO
Setup: Image Generator Post-Training
To introduce our method, let’s establish the pieces of our post-training loop. A flow matchingDoes this image match the caption [CAPTION]? Answer Yes or No. We can then use the likelihood of the ‘Yes’ token as a scalar reward. Our goal is to update the flow model so that it produces images that score higher under this reward (i.e., match the caption). By optimizing this reward, we’re pushing the model’s output distribution to concentrate on images that match the prompt, which is exactly the kind of distribution sharpening we’re hoping to get from post-training. This is natural to formulate as an RL problem.
Background: The Denoising MDP
Currently, the most popular algorithm for RL post-training image generators is the denoising Markov decision process (MDP). Introduced in DDPO
Standard policy gradient methods like PPO
Credit assignment is also challenging under this formulation. When a trajectory leads to high reward, each perturbation along it gets reinforced, even though most were irrelevant to increasing reward. Much of the update is noise that pushes the flow in reward-neutral directions.
We decided to build an algorithm outside the denoising MDP framework and started by just looking for the most direct way to push a flow model’s outputs toward higher reward.
The Direct Approach
For now, let’s assume the reward is differentiable (we’ll relax this later). Then, we can backpropagate through the VLM to get a gradient in image space. This represents the direction to shift the output image to produce greater reward. Flow models generate images through multiple denoising steps, each with its own predicted velocity, so we need to translate our image-space gradient into update directions for every velocity prediction along the sampling chain. The obvious way to do this is to backpropagate through the chain itself.
It’s worth analyzing what the backpropagation is doing mechanically. Each step’s Jacobian transforms the gradient one step backward through the chain. Composing all of them brings the image-space gradient all the way up to the initial noise.
The plot below shows this for a 2D flow, where we can visualize how different gradient directions transform along the chain. We sample an initial noise $x_0$ and transport it to the data distribution (in this case, a fractal distribution) by integrating the flow step-by-step. A reward gradient (computed through a differentiable reward) is defined at the data sample and then carried up the sampling chain by multiplying by each step’s Jacobian.
Existing methods
The chain of Jacobians is useful despite its flaws, since it gives us update directions for the velocity at every step, which we can train into the model. We propose a simple approximation that produces these per-step updates while avoiding the gradient problems, based on the following observations about the geometry of the optimization and underlying flow:
-
An update doesn’t have to exactly match the gradient to be useful. More precisely, a valid ascent direction is any direction at an angle of less than 90° from the true gradient, i.e., it lies in the same half-space. These ascent directions will still locally improve the reward, albeit less than the steepest direction. In fact, it’s a standard practice to update along directions that deviate from the true gradient even when it’s available. Adam rescales the gradient per-coordinate, while Muon rebalances its principal components. Both lead to better optimization properties than naive SGD.
-
Flow matching models are tuned to produce flows with minimal curvature, since those require fewer steps at inference time. This straightness property is useful for us. Intuitively, if the flow is straight, then a gradient computed on the final sample will be a valid ascent direction for intermediate steps along the trajectory. Mathematically, this corresponds to the Jacobian of the flow being positive semi-definite: it can stretch and scale, but it doesn’t rotate a gradient more than 90°. Optimal transport flows, the theoretical ideal, have exactly positive semi-definite Jacobians. While learned flows aren’t equivalent to optimal transport, it is still a reasonable approximate mental model.
A Simple Alternative
This motivates a simple alternative: instead of backpropagating through the sampling chain, just copy the image-space gradient up to all earlier steps. The argument from the previous section suggests this is a valid direction at each step, as long as the flow isn’t too rotational. Here we show the backpropagated gradient next to a simple copy:
Perhaps surprisingly, we find this works better than the exact backpropagated gradient. The copied gradient is biased, but it has dramatically better conditioning. It preserves the full frequency spectrum at every step, providing a clean image-aligned training signal, just like in pretraining. Our ablations confirm this. Using the true reward gradient applied uniformly to all steps (light brown in the figure below and row I in paper figure 8) performs comparably to our full method. However, backpropagating that gradient through the sampling trajectory (dark brown, row J figure 8) is significantly worse.
Extending to Non-Differentiable Rewards
Everything so far still requires a differentiable reward model to compute the image-space gradient. We want to make our method compatible with any scalar reward, including human feedback, external tools and black-box metrics, which is the general RL scenario.
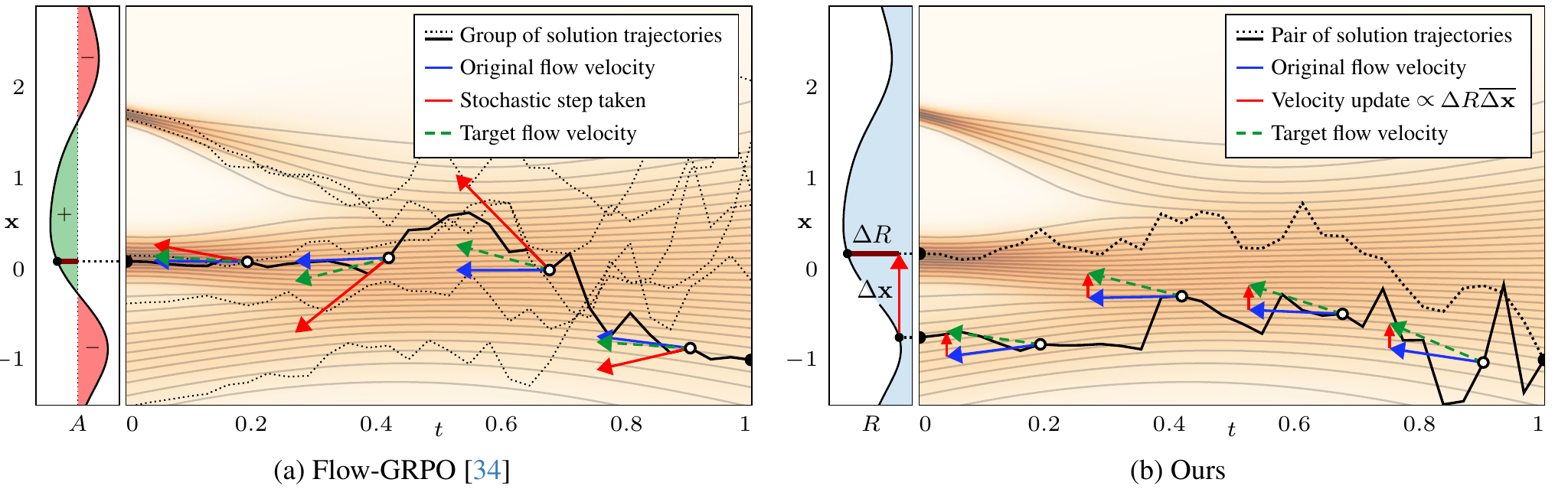
So far, we’ve assumed that the reward is differentiable. To handle any scalar reward, we use a simple mechanism: generate a pair of images from the same starting noise but introduce stochasticity during sampling so that they diverge into two similar, counterfactual images.

One image typically yields a higher reward than the other. The difference between the two images, weighted by their reward difference, gives us a direction that points from the worse image toward the better one. This is effectively a finite difference that tells us how reward varies along the direction the two images differ. We use this as our update direction and apply it uniformly across the flow, just as we did with the differentiable reward gradient. The paper analyzes this more rigorously, but the method itself is as simple as that.
FDFO Algorithm
- Sample two images from the same initial noise with slight stochasticity.
- Evaluate the reward for each image.
- Multiply the image difference by the reward difference.
- Update the model's velocity prediction toward this direction at each noise level.
Highlighted Results
We tested FDFO by post-training Stable Diffusion 3.5
The quality of training also differs. Flow-GRPO periodically produces grid-like artifacts during extended training which fade in and out but can be severe. We don’t observe these with our method, even after equally long training. Flow-GRPO also shows consistent style drift across prompts, which we attribute to its noisier updates causing random mutation in reward-irrelevant dimensions.
Before post-training, the base model’s output quality without CFG is poor. Enabling CFG dramatically improves alignment and quality, which is why it’s standard practice. After post-training with our method, the model produces high-quality, well-aligned images on its own, without CFG. Re-enabling CFG at that point mainly reduces diversity and introduces the characteristic high-contrast look, with debatable benefit. Interestingly, our method reaches similar reward levels regardless of CFG scale.












Independent metrics support these findings. OneIG-Bench
Grad Student Reward Function
Everything so far has used VLM rewards, which tend to prefer a very “AI” look when you ask them to score images quality. We wanted to try something more interesting: human preferences, directly on-policy.
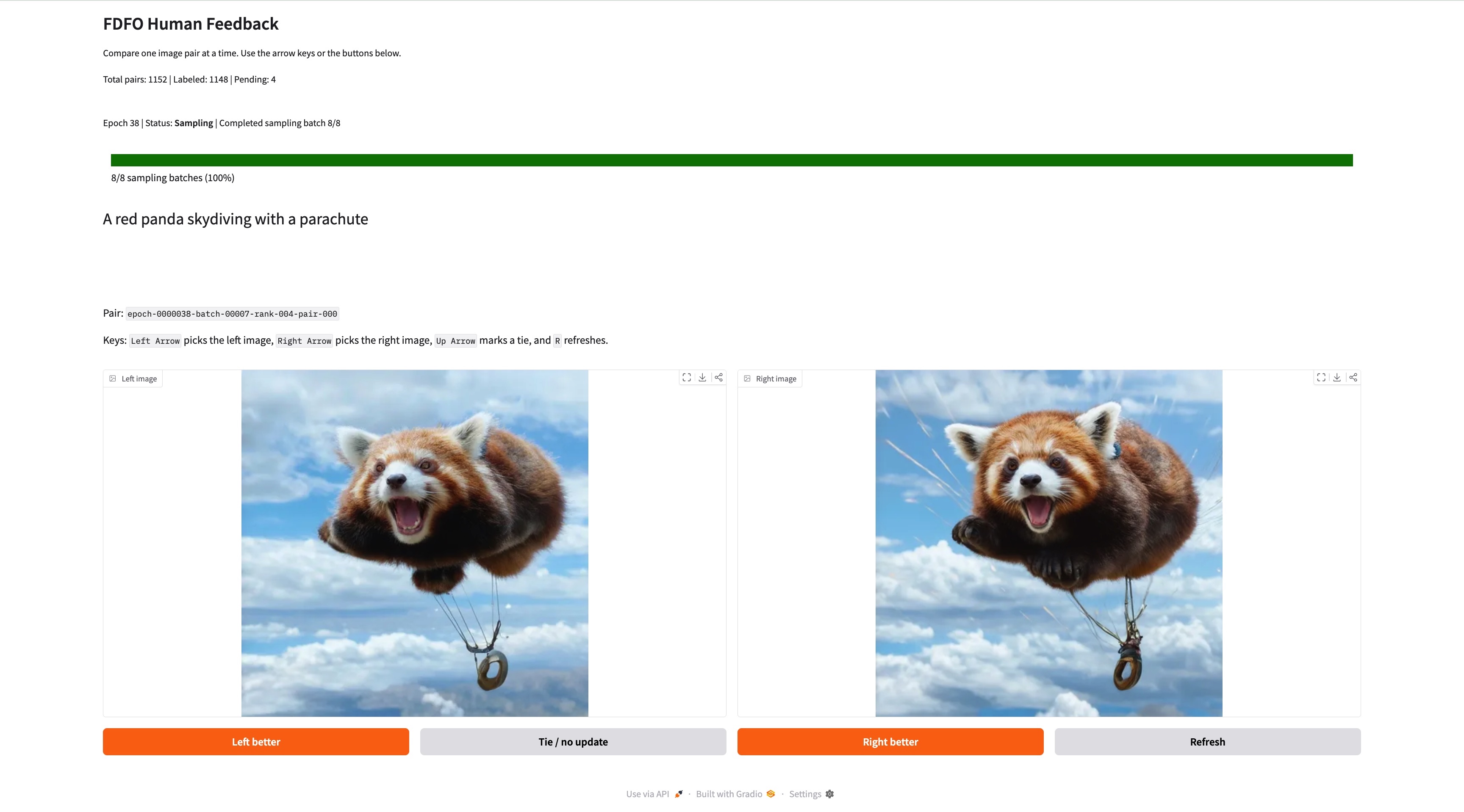
FDFO is well-suited to this. It doesn't require differentiable rewards, and humans aren't differentiable. It's on-policy and sample-efficient, so you can watch the model respond to your feedback in near real-time. And because the method already compares pairs of images, it maps naturally onto a simple UX: show the rater two images at a time, and let them pick the better one.
We built a simple web GUI that generates a batch of image pairs, lets the user select their preferred image from each pair (or indicate no preference), and then trains on the batch for about 30 seconds before serving the next round. Starting from Stable Diffusion 3.5 Medium with a LoRA
One practical finding from this experiment: updating the model uniformly at all noise levels is important. It allows the RL to correct both low-frequency structure (composition, layout) and high-frequency detail (textures, sharpness) simultaneously. We observed this with VLM rewards too, but it showed up much more prominently with this higher quality reward signal. Here are some enlarged images where you can see details added during post-training:
 Before
Before  After
After  Before
Before  After
After What made this work well in practice was the on-policy RL loop: at every step, I was looking at what the current model actually produces and nudging it in the direction I preferred. The model’s outputs improved visibly between rounds, which made the process feel manageable even over hundreds of decisions. This kind of iterative shaping of a model’s output distribution is one of the things RL is uniquely good at. In total, this required labeling just 3,200 pairs of images and imparted a visual style on the model that matched my preferences. It’s exciting to think about how this could be extended to shape a model’s aesthetic at scale, or even personalized to individual users.
Takeaways
Our main takeaway from this project is that the structure of the generative process matters for how you do RL on it. We found that working with this structure rather than against it led to a simpler algorithm that performs better.
A specific instance of this: policy gradient methods rely on the gradient of the log-likelihood, not the likelihood itself. Likelihoods are notoriously hard to estimate in flow models, so we decided not to try. This opened up a more direct path to the reward gradient. We suspect there are more wins like this, where the properties of flows make certain things easier than the imported RL framework assumes.
There are still important open questions. Retaining diversity during RL optimization is difficult, and KL regularization isn’t a satisfying solution. Also, aspects of image quality not covered by the reward can quietly degenerate, so making rewards comprehensive enough to avoid early stopping is a challenge in its own right. We see FDFO as a clean starting point for working on these problems.